
Dryrunning a Trap ⛓️
Ideally you would be able to test your trap with real block/state data before deploying it for real, on-chain. Well, with the dryrun command you can. In normal trap operation, a trap will be "monitored" by one or more opted-in operators, but with the dryrun command you can easily test two lifecycles (a bootstrap and a normal lifecycle) of this same process on your local machine with what is for all intents and purposes, a locally spun-up ad-hoc operator.
Under The Hood
The lifecycle will be performed with block(s) pulled from your specified evm endpoint, ethereum_rpc in your drosera.toml config file. The number of blocks pulled is determined by your configured block_sample_size (also drosera.toml) for the trap.
Lifecycle
-
The
block_sample_sizelatest blocks are processed by the trap'scollectfunction:-
Bootstrap Lifecycle: For the first lifecycle, the system starts from scratch with no cached data. It fetches each block from your RPC endpoint and runs the
collectfunction on it. During this process, account and slot data are fetched one by one, as needed during trap (solidity contract) execution. All account addresses and slot indexes data are then cached for future use. -
Runtime Lifecycle: For subsequent lifecycles, the cached account addresses and slot indexes are used for
collectcalls. This onecollectruns faster because the account and slot data is pre-fetched in a batch call, so the trap runs much faster due to significantly less RPC calls being made.
-
-
The outputs of the
collectcalls are passed as input to one call of theshould_respondfunction. -
should_respondwill return a value offalsefor do nothing, ortruefor execute the specifiedresponse_function(drosera.toml).
You've now been able to verify that your trap is functioning end-to-end, as if it was already deployed to the Drosera network.
Example
Command: drosera dryrun
When running, the progress bar will show the progress of the dryrun for each trap. Progress is indicated by the block_sample_size for each trap. The progress bar will also show the trap name and the index of the block that is being processed.

Once completed, the output will be displayed in the terminal like this:
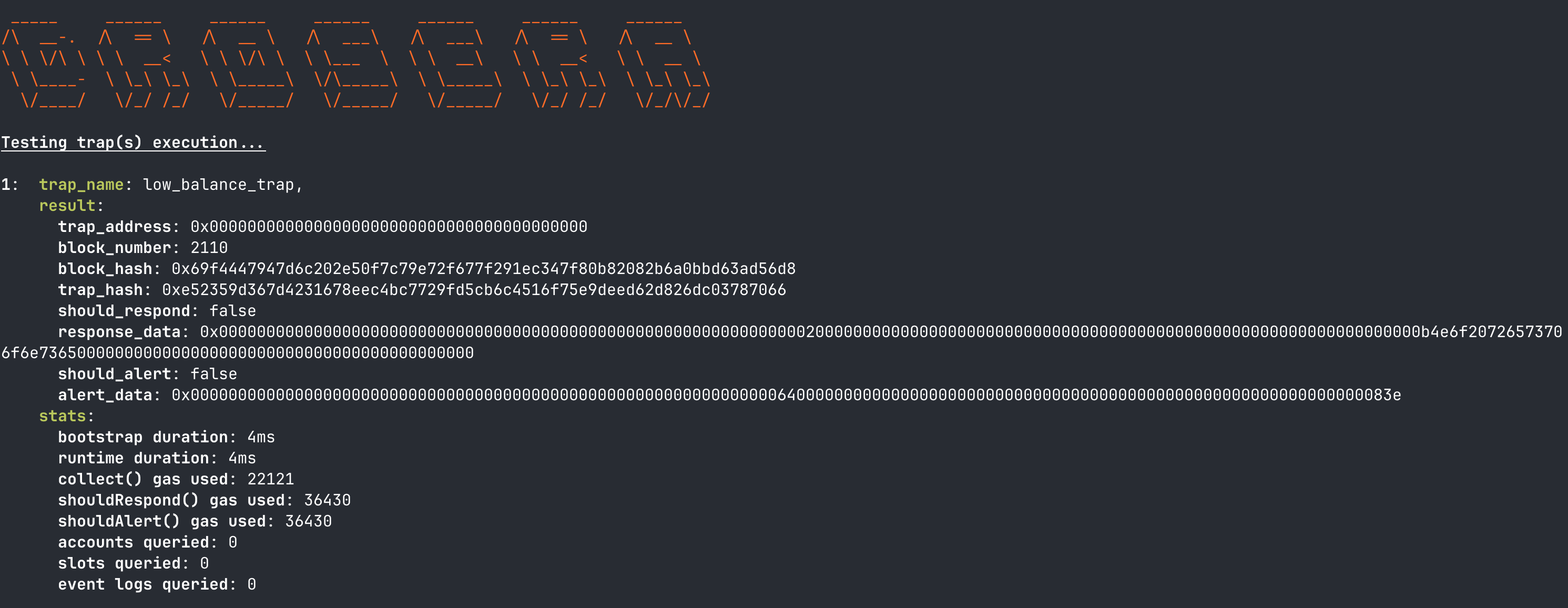 This trap has a
This trap has a block_sample_size of 10 in this example. The first block processed will take the longest, this is the bootstrap lifecycle. The bootstrap lifecycle starts with no cached accounts or slot indexes so it has to perform all of the computation and block fetching, resulting in a longer lifecycle time.
For subsequent blocks, this is the runtime lifecyle. In the runtime lifecycle, it speeds through collects for blocks 2, 3, 4, 5, 6, 7, 8, 9, and 10 because the account addresses and slot indexes required by the trap are known.
Reference
trap_name: The name of the trap in thedrosera.tomlconfig fileresult: The result of the trap execution.trap_address: The address of the trap config. (will be zero if Trap Config has not been created yet)block_number: The block number that the trapsshouldRespondandshouldAlertfunctions were executed on.block_hash: The hash of the block that the trapsshouldRespondandshouldAlertfunctions were executed on.trap_hash: The hash of the trap bytecode.should_respond: Whether the trap should respond.response_data: The data returned by theshouldRespondfunction if the trap should respond.should_alert: Whether the trap should alert.alert_data: The data returned by theshouldAlertfunction if the trap should alert.
stats: The runtime statistics of the trap execution.bootstrap duration: The duration of the bootstrap lifecycle. (Bootstrap lifecycle takes longer than runtime lifecycle which affects the startup time of the trap. Only in affect once)runtime duration: The duration of the runtime lifecycle for processing new blocks. (Normal lifecycle)collect() gas used: The gas used by thecollectfunction.shouldRespond() gas used: The gas used by theshouldRespondfunction.shouldAlert() gas used: The gas used by theshouldAlertfunction.accounts queried: The number of accounts queried.slots queried: The number of slots queried.event logs queried: The number of event logs queried and provided to the Trap for the specified block number.
Theory-crafting
With the optional --block-number argument, dryrun can be used to test traps on past state. This allows anything from more robust testing of a trap, all the way to verifying that a trap successfully catches a past exploit. An excellent addition to the security researcher tool belt.
How To Run
drosera dryrun --block-number <block_number>where --block-number is optional. Without, it defaults to the current block number.
Lifecycle Limitations
With traps, you have significantly more gas to work with than a contract on-chain. Blocks on Ethereum currently have a total block.gasLimit of ~30 million gas units. So the sum of gas used by all transactions in a block cannot excede this number. In another stratosphere, Drosera is configured to allow up to 1 billion gas units per collect function and 1 billion gas units per shouldRespond function. This means that one trap lifecycle with a block_sample_size of 1 could use up to 2 billion gas units, or approximately 66x more gas than what can fit in an entire Ethereum block.
But, with great power comes great responsibility. Ethereum blocks average about 12 seconds per block, and so in order for a trap to retain its ability of responding in the next block after the configured condition is detected (shouldRespond returns true), it needs to be able to be executed within a few seconds by the recommended system requirements. If the trap takes too long to execute on recommended spec operator hardware, then the operators running the trap will struggle or be unable to keep up with Ethereum block times and begin falling further and further behind.
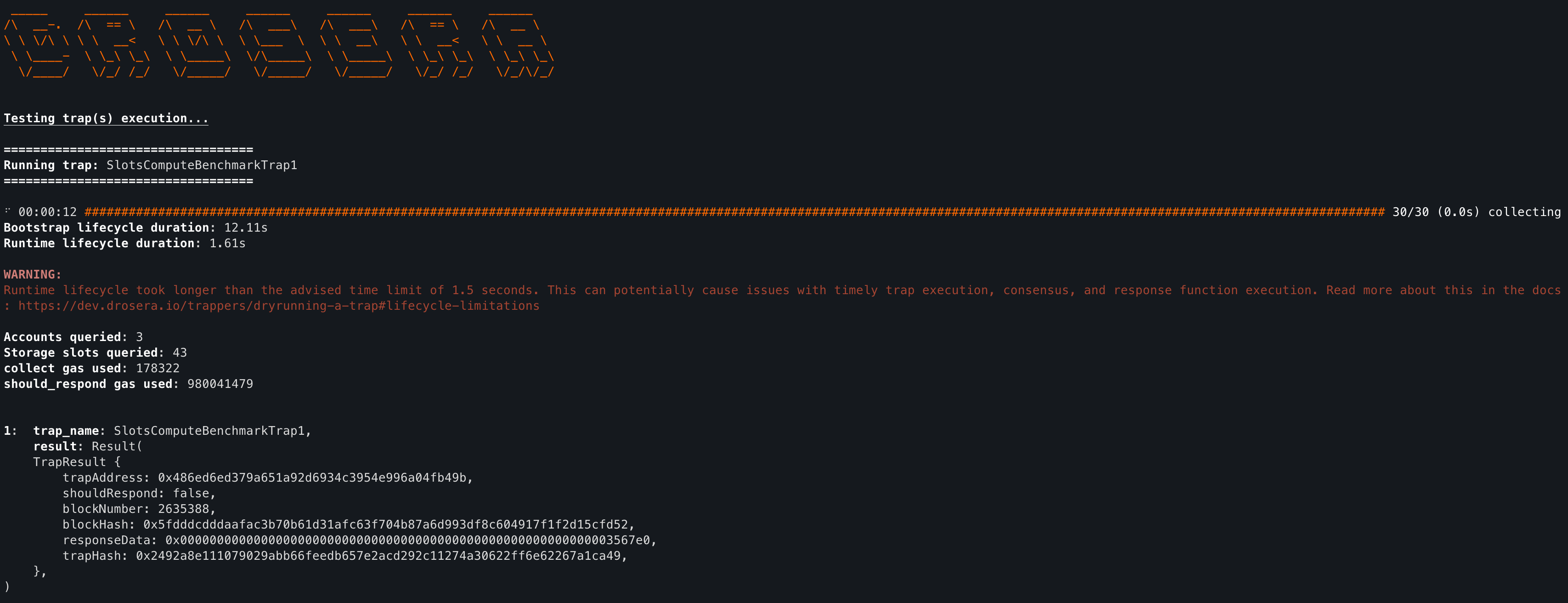
Therefore dryrun has a safety check built in. If a trap's normal lifecycle (>= 2nd lifecycle) takes longer than a recommended upper time limit, it will emit a warning. dryrun is running on your local computer, so if your computer specs are equal to or lower than the recommended operator specs, this trap (when deployed) may struggle or entirely fail to keep up with on-chain blocks, thus falling behind and either reducing the effectivness of the trap or defeating its security use case entirely. If your computer specs are better than the recommended operator specs, and dryrun yields this warning, the trap will most certainly have the previously mentioned issues when deployed. Additionally, for certain trap designs querying many accounts/slots, RPC latency may be a factor at play here as well.